
内存堆栈管理
内存堆栈管理概述
内存管理是计算机系统中的核心概念,在ARM架构中,内存主要分为栈(Stack)和堆(Heap)两种类型。本文将详细介绍这两种内存类型的管理机制、特点以及在ARM架构下的具体实现。
栈的管理
1.1 栈的基本概念
栈是一种**先进后出(LIFO)**的数据结构,是C语言运行的基础。C语言函数中的局部变量、传递的实参、返回的结果以及编译器生成的临时变量都保存在栈中。
1.1.1 栈的基本操作
栈有两种基本操作:
- 压栈(push): 将数据存入栈中
- 弹栈(pop): 从栈中取出数据
ARM架构中使用SP寄存器(Stack Pointer,R13)作为栈指针,用于维护栈的这两种操作。
1.1.2 栈的分类
根据栈指针SP指向栈顶元素的不同,栈可分为:
- 满栈(Full Stack): SP总是指向栈顶元素
- 空栈(Empty Stack): SP总是指向栈顶元素的下一个可用位置
根据栈的生长方向不同,栈又分为:
- 递增栈(Ascending Stack): 栈从低地址向高地址增长
- 递减栈(Descending Stack): 栈从高地址向低地址增长
ARM架构中常用的是满递减栈(Full Descending Stack),本文主要叙述这种栈类型。
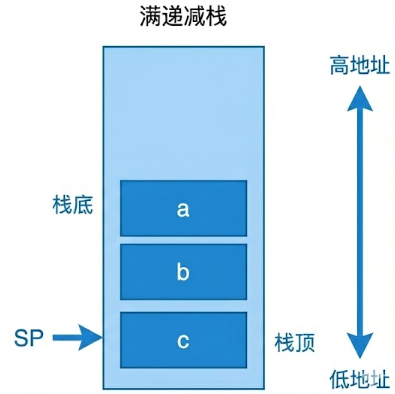
如上图所示,满递减栈的栈指针SP总是指向栈顶元素,当有新元素入栈时,栈指针先从高地址向低地址移动,然后把新元素放入SP指向的空间。出栈顺序则刚好相反,先弹出栈顶元素,然后栈指针向高地址移动,指向下一个栈顶元素。
1.2 栈的初始化
栈的初始化其实就是栈指针SP的初始化。在系统启动过程中,内存初始化后,将栈指针指向内存中的一段连续空间,就完成了栈的初始化。栈指针指向的这片内存空间被称为栈空间。
- 栈初始化后,SP指向栈空间的栈顶
- 当进行入栈、出栈操作时,SP会随着栈顶的变化上下移动
- 在栈的初始化过程中,除了指定栈的起始地址,还需要指定栈空间的大小
- ARM处理器使用R13寄存器(SP)和R11寄存器(FP)来管理堆栈,FP用于指向栈帧的底部
1.3 函数调用与栈帧
1.3.1 栈帧的概念
每一个函数在调用时都会在栈中分配专门的空间,这个空间被称为栈帧(Frame Pointer, FP)。每个栈帧都使用两个寄存器来维护:
- FP指向栈帧的底部
- SP指向栈帧的顶部
函数的栈帧主要用于保存:
- 局部变量
- 函数实参
- 函数调用者的返回地址
- 上一级函数栈帧的起始地址(FP)
- 函数的上下文信息
- 编译器生成的临时变量(可选)
1.3.2 函数调用链
一个程序中往往存在多级函数调用,每一级调用都会运行不同的函数,每个函数都有自己的栈帧空间。上一级函数栈帧的起始地址(FP)会保存到当前函数的栈帧中,多个栈帧通过FP构成一个链,这个链就是函数调用栈。
调试器支持的回溯功能就是基于这个调用链来分析函数的调用关系的。
1.4 参数传递机制
函数调用过程中的参数传递,一般有两种方式:
1.4.1 基于寄存器的参数传递
ARM处理器为了提高程序运行效率,会优先使用寄存器来传参。根据**ATPCS(ARM-Thumb Procedure Call Standard)**规则:
- 当参数个数小于4时,直接使用R0~R3寄存器传递
- 当参数个数大于4时,前4个参数使用寄存器传递,剩余的参数则压入堆栈保存
1.4.2 基于栈的参数传递
对于超出寄存器数量限制的参数,或者某些特殊类型的参数,会使用栈来传递。这些参数会被压入调用者的栈帧中,供被调用函数访问。
1.5 形参和实参
1.5.1 值传递的本质
C语言中函数的参数传递是值传递,形参保存的是实参的副本。
- 形参只有在函数被调用时才会在栈中分配临时的存储单元,用来保存传递过来的实参值
- 函数运行结束后,形参单元随着栈帧的销毁而被释放
1.5.2 形参和实参的关系
变量作为实参传递时,只是将变量值复制给了形参,形参和实参在栈中位于不同的存储单元。因此:
- 在函数运行期间,改变形参的值并不会改变原来实参的值
- 函数对形参的任何修改都不会影响到实参变量本身
1.6 栈与作用域
1.6.1 全局变量
- 定义在函数体外
- 作用域范围:从声明处到文件结束
- 其他文件可通过
extern声明后使用 - 生命周期:整个程序运行期间
1.6.2 局部变量
- 定义在函数内
- 作用域范围:仅在函数体内使用
- 生命周期:仅存在于函数运行期间
- 每次函数被调用时,会在栈中重新分配栈帧空间,因此局部变量的地址可能不同
1.6.3 块级作用域
编译器在编译程序时,根据一对大括号{}来限定变量的作用域。在大括号内部定义的变量,只能在大括号内部使用。
例如:
int main(void) |
static关键字虽然改变了局部变量的存储属性(从栈空间移到静态存储区),延长了其生命周期,但作用域仍然由{}决定。
堆的管理
2.1 堆与栈的比较
堆内存与栈内存相比,具有以下特点:
| 特性 | 堆内存 | 栈内存 |
|---|---|---|
| 分配方式 | 动态分配,由程序员手动申请和释放 | 自动分配,由编译器管理 |
| 访问方式 | 匿名的,通过指针间接访问 | 通过变量名或栈指针相对寻址访问 |
| 生命周期 | 由程序员控制,函数退出时不会自动释放 | 函数运行时分配,函数结束时自动释放 |
| 内存结构 | 不连续,容易产生碎片 | 连续的内存块 |
| 分配效率 | 较低 | 较高 |
2.2 堆内存的分配与释放
当用户使用malloc()函数申请一片内存时,需要从堆内存中分配;当使用free()函数释放一片内存时,将这片内存归还到堆内存中。堆内存自身需要专门的管理和维护,以应对用户的内存申请和释放请求。
2.3 裸机下的堆内存管理
在裸机开发环境中,如Keil MDK:
2.3.1 堆的定义
在启动文件startxx.s中定义了堆的起始地址和大小: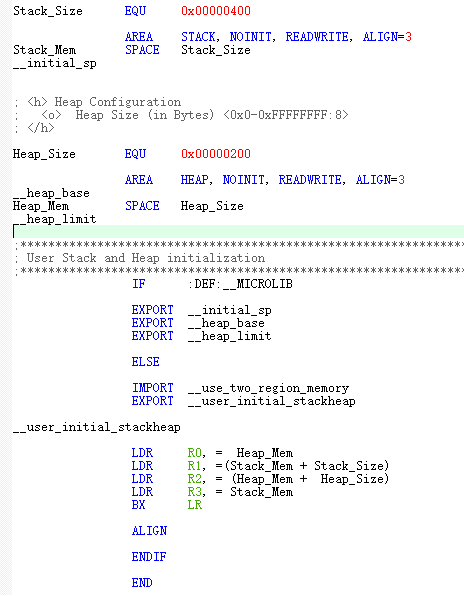
2.3.2 堆管理的实现
Keil编译器实现了一个简化版的C标准库,称为MicroLIB。该库实现了C标准规定的大部分函数功能(如malloc、memcpy等),并针对嵌入式平台做了优化,使其体积更小,更适合资源有限的嵌入式系统。
2.3.3 内存碎片化问题
在裸机环境下,一片连续的堆内存空间经过多次小块内存的申请和释放后,会造成内存碎片化,在内存中留下越来越多、越来越小的空闲内存块。此时如果再申请一片连续的大块内存,即使总的空闲内存足够,也可能因为没有连续的空闲块而失败。
2.3.4 内存碎片化的解决方案
在嵌入式裸机环境下,有几种方法可以应对内存碎片化问题:
- 避免使用堆内存:遇到需要使用大块内存的地方,可以使用全局数组代替
- 实现自定义内存池:将堆内存空间划分为固定大小的内存块,自己管理与维护内存的申请和释放
- 多内存池策略:将堆内存划分为不同大小的内存块池,根据用户申请内存的大小选择合适的内存块,提高内存利用率
2.4 FreeRTOS下的堆内存管理
FreeRTOS提供了多种堆内存管理方案,以适应不同的应用场景:
2.4.1 FreeRTOS的内存管理方案
FreeRTOS提供了5种内存管理方案(heap_1.c到heap_5.c),从简单到复杂,满足不同的需求:
- heap_1:最简单的实现,只支持内存分配,不支持释放
- heap_2:支持内存分配和释放,但可能产生碎片
- heap_3:简单包装了标准C库的malloc和free函数
- heap_4:支持内存分配和释放,通过合并相邻空闲块减少碎片
- heap_5:在heap_4的基础上,支持非连续的内存块
2.4.2 选择合适的内存管理方案
选择FreeRTOS内存管理方案时,需要考虑以下因素:
- 应用对内存的需求
- 系统资源的限制
- 对内存碎片的容忍度
- 实时性要求
内存泄漏
3.1 内存泄漏的概念
在C函数中,如果使用malloc()等函数申请的内存在使用结束后没有及时被释放,就会造成内存泄漏。此时,C标准库中的内存分配器和内核中的内存管理子系统都失去了对这块内存的追踪和管理。
内存泄漏会导致:
- 可用内存逐渐减少
- 系统性能下降
- 严重时可能导致系统崩溃
3.2 内存泄漏的预防
预防内存泄漏的最佳实践:
- 配对使用内存操作函数:内存申请后及时释放,确保
malloc()与free()配对使用 - 释放内存后置空指针:内存释放后将指针设置为
NULL,避免悬空指针 - 使用内存前检查:使用内存指针前进行非空判断
- 采用RAII设计模式:在C++中可使用智能指针等机制自动管理内存
- 使用内存泄漏检测工具:如Valgrind等工具帮助检测内存泄漏
总结
本文详细介绍了ARM架构下的内存堆栈管理:
栈管理:
- 栈是先进后出的数据结构,由编译器自动管理
- ARM使用满递减栈,SP寄存器指向栈顶元素
- 函数调用时创建栈帧,保存局部变量、参数和返回地址
- 参数传递优先使用寄存器(R0-R3),超出部分使用栈
堆管理:
- 堆是动态分配的内存,由程序员手动管理
- 裸机环境下需要注意内存碎片化问题
- FreeRTOS提供了多种内存管理方案
内存泄漏:
- 申请的内存未及时释放会导致内存泄漏
- 预防内存泄漏需要配对使用内存操作函数,释放后置空指针
理解内存堆栈管理对于编写高效、稳定的嵌入式程序至关重要。在实际开发中,应根据具体应用场景选择合适的内存管理策略。