
编译过程
为什么要了解编译原理
在嵌入式开发的世界里,处理器平台和软件生态呈现碎片化、多样化的特点。不同的嵌入式系统往往采用更灵活的配置:不同的CPU平台、不同大小的存储、不同的启动方式。因此,我们不仅要编写代码,还需要考虑将程序代码”烧”写到什么地方、加载到内存什么位置、如何执行——我们必须理解代码从源文件到在特定内存地址运行的完整历程,才能根据硬件平台的差异灵活地完成软件层面的编译优化和配置。
编译的大概过程
编译就是将C程序中定义的函数、变量分类后,分别放置在可执行文件的代码段、数据段和BSS段中;程序中定义的字符串、printf函数打印的字符串常量则放置在只读数据段(.rodata)中。
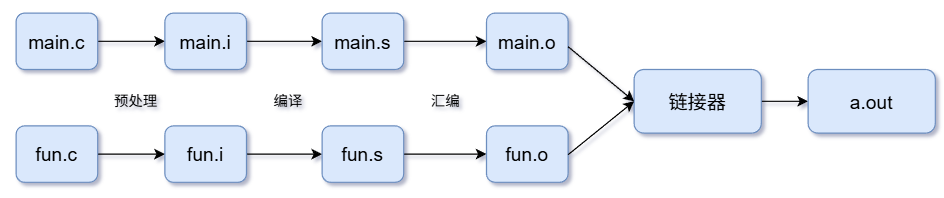
编译过程主要包含以下几个步骤:
- 预处理器:将源文件main.c经过预处理变为main.i
- 编译器:将预处理后的main.i编译为汇编文件main.s
- 汇编器:将汇编文件main.s编译为目标文件main.o
- 链接器:将各个目标文件main.o、fun.o等链接成可执行文件a.out
注意:汇编器生成的目标文件是可重定位的目标文件,本身不可执行,需要经过链接器的链接、重定位之后才能运行。
编译的具体过程
预处理(预处理器)
预处理过程是在编译源程序之前,先处理源文件中的各种预处理命令。编译器不识别预处理指令,如果在编译前不先处理这些预处理命令,编译器会报错。预处理主要包括以下操作:
- 头文件展开:将
#include包含的头文件内容展开到当前位置 - 宏展开:展开所有的宏定义,并删除
#define指令 - 条件编译:根据宏定义条件,选择要参与编译的分支代码,其余分支丢弃
- 删除注释:移除代码中的注释内容
- 添加行号和文件名标识:编译过程中根据需要显示这些信息
- 保留
#pragma命令:该命令会在程序编译时指示编译器执行一些特定行为
编译(编译器、汇编器)
编译阶段主要分为两步:
- 编译器调用一系列解析工具分析C代码,将C源文件编译为汇编文件
- 汇编器将汇编文件汇编成可重定位的目标文件
编译过程
C源文件到汇编文件的转换,实际上是将C文件中的程序代码块、函数转换为汇编程序中的代码段,将C程序中的全局变量、静态变量、常量转换为汇编程序中的数据段、只读数据段。
总体来说,编译过程分为以下六步:
- 词法分析:将源程序分解为一系列不能再分解的记号单元(token)
- 语法分析:对token序列进行解析,构建语法上正确的语法树
- 语义分析:检查语法分析输出的表达式、语句是否存在语义错误(如类型不匹配、未声明变量等)
- 中间代码生成:将语法树转化为中间代码,中间代码是一维线性序列结构,类似伪代码(与平台无关)
- 汇编代码生成:参考ARM指令集,根据ATPCS规则分配寄存器,将中间代码翻译成ARM汇编程序
- 目标代码生成:优化汇编代码,生成最终的目标代码
汇编过程
汇编过程是使用汇编器将前一阶段生成的汇编文件翻译成目标文件。汇编器的主要工作是参考指令集架构(例如ARM Cortex-M的Thumb指令集),将汇编代码翻译成对应的二进制指令,同时生成必要的信息,以section的形式组装到目标文件中,供后续链接过程使用。
汇编器处理过后的.o文件是不可执行的,属于可重定位目标文件,需要经过链接器的重定位、链接之后,才能组装成可执行的目标文件。
符号与重定位的概念
编译器在将源文件翻译成可重定位目标文件的过程中,会将不同的函数编译成二进制指令后,从零地址开始依次将每个函数的指令序列存放到代码段中,每个函数的入口地址也就从零地址开始依次往后偏移。因此,在每个可重定位目标文件中,函数或变量的地址其实就是它们在文件中相对于零地址的偏移。
然而,在链接过程中,链接器将各个目标文件组装在一起时,各个目标文件的参考起始地址会发生变化,因此目标文件内的函数或变量的地址也需要随之更新,否则我们无法通过函数名引用函数、通过变量名引用变量。这个过程称为重定位。
一个文件中的所有符号(无论是函数名还是变量名),无论其是否需要重定位,汇编器都会收集起来,生成一个符号表,以section的形式添加到每一个可重定位目标文件中。在整个编译过程中,符号表主要用来保存源程序中各种符号的信息,包括符号的地址、类型、占用空间的大小等。符号表本质上是一个结构体数组,每个符号都有符号值和类型。
编译器是以C源文件为单位编译程序的。如果在一个C源文件中引用了在其他文件中定义的函数或全局变量,只要在调用之前进行声明,编译器就会认为这些符号可能在其他文件或库中定义,在编译阶段暂时不会报错。在链接过程中,链接器会尝试在其他文件或库中查找这些符号的定义,如果找不到才会报错(链接错误)。
编译器在给每个目标文件生成符号表时,如果在当前文件中没有找到符号的定义,也会将这些符号搜集在一起并保存到一个单独的符号表中,以待后续填充,这个符号表就是重定位符号表。重定位表中的符号所关联的地址,在后续链接过程中经过重定位后,会更新为新的实际地址。
总结一下上面说的
在C项目的编译过程中,编译器以C源文件为单位,将一个个C文件翻译成对应的目标文件。每个目标文件都由代码段、数据段、BSS段、符号表等section组成。这些section从目标文件的零偏移地址开始按顺序排放,每个段中的符号相对于零地址的偏移,就是每个符号的地址,这样程序中定义的变量、函数名等就有了一个暂时的地址。
在链接过程中,这些目标文件中的各个section会重新拆分组装,每个section的起始参考地址都会发生变化,导致每个section中定义的函数、全局变量等符号的地址也需要随之修改,这个过程就是重定位。
链接(链接器)
链接主要分为三个过程:分段组装、符号决议、重定位。
分段组装
链接器将编译器生成的各个可重定位目标文件重新分解组装:将各个目标文件的代码段放在一起,作为最终可执行文件的代码段;将各个目标文件的数据段放在一起,作为可执行文件的数据段。其他section也会按照同样的方法进行组装,最终生成可执行文件的雏形。
链接器会在可执行文件中创建一个全局符号表,收集各个目标文件符号表中的符号并统一存放。此时,可执行文件中的所有符号都有了自己的地址,但这些地址仍然是原来在各个目标文件中的地址(即相对于零地址的偏移)。
链接生成的可执行文件最终要被加载到内存中执行,因此需要指定加载到内存中的位置。通常,程序在链接时需要指定一个链接起始地址,这个地址一般就是程序要加载到内存中的地址。在链接过程中,各个段在可执行文件中的先后组装顺序也需要考虑,可执行程序的入口地址部分通常会放在前面。
要指定程序的链接地址和各个段的组装顺序,可以通过链接脚本实现。链接脚本本质上是一个脚本文件,不仅规定了各个段的组装顺序、起始地址、位置对齐等信息,还详细描述了输出的可执行文件格式、运行平台、入口地址等信息。链接器根据链接脚本定义的规则组装可执行文件,并将这些信息以section的形式保存到可执行文件的ELF Header中。
符号决议
链接器允许一个项目中出现多个弱符号共存。在程序编译期间,编译器分析每个文件中未初始化的全局变量时,不知道该符号在链接阶段是被采用还是被丢弃,因此未初始化的全局变量并没有直接放置在BSS段中,而是将这些弱符号放到一个叫作COMMON的临时块中,在符号表中用未定义的COMMON标记,并且在目标文件中不分配存储空间。
在链接期间,链接器会比较多个文件中的弱符号,选择占用空间最大的那个作为可执行文件中的最终符号。此时,弱符号的大小已经确定,并被直接放到可执行文件的BSS段中。
与强符号、弱符号对应的,还有强引用、弱引用的概念。在程序中,我们可以定义多个函数和变量,变量名和函数名都是符号,这些符号的本质(符号值)其实就是地址。在另一个文件中,我们可以通过函数名调用函数,通过变量名访问变量。这种通过符号调用函数或访问变量的行为通常称为引用(reference),强符号对应强引用,弱符号对应弱引用。
在程序链接过程中,若对一个符号的引用为强引用,链接时找不到其定义,链接器将会报未定义错误;若对一个符号的引用为弱引用,链接时找不到其定义,链接器不会报错,也不会影响最终可执行文件的生成。可执行文件在运行时如果仍然找不到该符号的定义才会报错。
重定位
经过符号决议,我们解决了链接过程中多文件符号冲突的问题。此时,可执行文件的符号表中的每个符号虽然都已确定,但符号表中的符号值(即每个函数、全局变量的地址)仍然是原来各个目标文件中的值,基于零地址的偏移。而链接器将各个目标文件重新分解组装后,各个段的起始地址都已发生变化。
程序重新分解组装后,无论是代码段还是数据段,各个符号的真实地址都发生了变化。因此,需要修改全局符号表中这些符号的值,将它们的真实地址更新到符号表中。修改完毕后,当我们通过符号引用调用函数或访问变量时,就能找到它们在内存中的真实地址了。
链接器如何知道哪些符号需要重定位呢?在各个目标文件中,有一个专门的重定位表,用于记录各个文件中需要重定位的符号。重定位的核心工作就是修正指令中的符号地址,这是链接过程中的最后一步,也是最核心、最重要的一步,前面的操作实际上都是为这一步服务的。
在编译阶段,编译器将各个C源文件生成目标文件时,遇到未定义的符号一般不会报错,而是认为这些符号可能在其他地方定义。只有在链接阶段,链接器在其他地方找不到该符号的定义时,才会报链接错误。编译器在编译阶段会搜集这些未定义的符号,生成一个重定位表,用于告诉链接器:”这些符号在文件中被引用,但在本文件中没有找到定义,可能在其他文件或库中定义,我先不报错,你链接的时候找找看”。
无论是代码段还是数据段,只要该段中有需要重定位的符号,编译器都会生成一个重定位表与其对应,如.rel.text(代码段重定位表)或.rel.data(数据段重定位表)。这些重定位表记录了各个段中需要重定位的符号,并以section的形式保存在各个目标文件中。
至此,整个链接过程就结束了,我们跟踪的整个编译流程也就完成了。最终生成的文件就是一个可执行目标文件。